
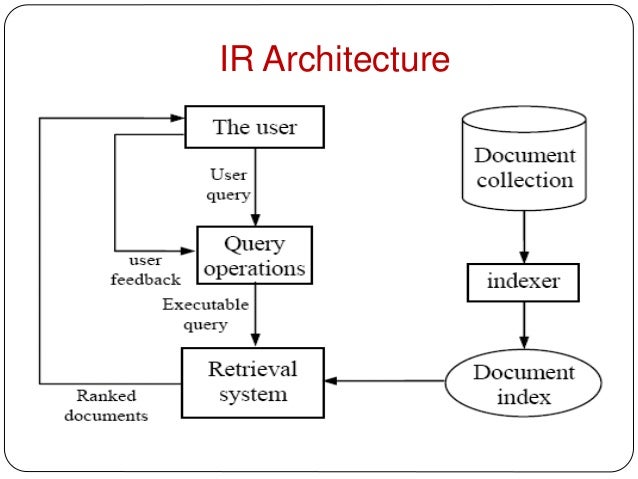
Information Retrieval Architecture and Algorithms
Navigation menu
An Overview of Current Research". Proceedings of the 5th International Conference on Collaborative Computing: Networking, Applications and Worksharing CollaborateCom' Archived from the original on Proceedings of the IEEE. Information Retrieval and Processing. Machine language; factors underlying its design and development". Information Processing and Management. Information Storage and Retrieval.
Retrieved from " https: Information retrieval Natural language processing. Views Read Edit View history. In other projects Wikimedia Commons Wikiquote. This page was last edited on 2 November , at By using this site, you agree to the Terms of Use and Privacy Policy. By this means the text of a document, preceded by its subject code symbol, ca be recorded Wikiquote has quotations related to: Wikimedia Commons has media related to Information retrieval. The book takes a system approach to explore every functional processing step in a system from ingest of an item to be indexed to displaying results, showing how implementation decisions add to the information retrieval goal, and thus providing the user with the needed outcome, while minimizing their resources to obtain those results.
Information retrieval - Wikipedia
The text stresses the current migration of information retrieval from just textual to multimedia, expounding upon multimedia search, retrieval and display, as well as classic and new textual techniques. It also introduces developments in hardware, and more importantly, search architectures, such as those introduced by Google, in order to approach scalability issues. A first course text for advanced level courses, providing a survey of information retrieval system theory and architecture, complete with challenging exercisesApproaches information retrieval from a practical systems view in order for the reader to grasp both scope and solutionsFeatures what is achievable using existing technologies and investigates what deficiencies warrant additional exploration.
Grand Eagle Retail is the ideal place for all your shopping needs! With fast shipping, low prices, friendly service and over 1,, in stock items - you're bound to find what you want, at a price you'll love! To insert a word into a signature, each of the hash functions is applied to the word and the corresponding bits set in the signature. The algorithm for doing this is as follows: A result of 0 is interpreted as absent and a result of 1 is interpreted as present.
Informace o předmětu
This, in turn, depends on the number of signatures per document. A randomly chosen document will have the length L , and require signatures. If the distribution of L is reasonably smooth, then a good approximation for the average number of signatures per document is: The number of signatures in a database is then and the VP ratio is We can now compute the average time per query term: These signatures can then be placed in consecutive positions, and flag bits used to indicate the first and last positions for each document. For example, given the following set of documents: For example, probing for "yet" we obtain the following results: The value at other positions is not meaningful.
In this algorithm a query consists of an array of terms. Each term consists of a word and a weight. The score for a document is the sum of the weights of the words it contains. It may be implemented thus: Times for Boolean queries will be slightly less than times for document scoring.
As a simplification, each query term may be: Here is a complete Boolean query engine: This operation is performed once per query term. We should then seek to pull the operation outside the query-term loop. This may be done by 1 computing the score for each signature independently, then 2 summing the scores at the end. This is accomlished by the following routine: The question arises, however, as to what this second algorithm is computing.
If each query term occurs no more than once per document, then the two algorithms compute the same result. If, however, a query term occurs in more than one signature per document, it will be counted double or even treble, and the score of that document will, as a consequence, be elevated. This might, in fact, be beneficial in that it yields an approximation to document-term weighting. Properly controlled, then, this feature of the algorithm might be beneficial. In any event, it is a simple matter to delete duplicate word occurances before creating the signatures.
- Hans Brinker or The Sliver Skates (Illustrated).
- Information retrieval architecture and algorithms?
- Account Options.
- Klokking Twelve: Snapshots of a Life.
- Information retrieval architecture and algorithms [electronic resource] in SearchWorks catalog.
- Walking the Walk.
Those algorithms assumed, however, that every position contained a document score. The signature algorithm leaves us with only the last position of each document containing a score. Use of the previously explained algorithms thus requires some slight adaptation. The simplest such adaptation is to pad the scores out with - 1.
- PV211 Introduction to Information Retrieval;
- Difficult Decisions in Thoracic Surgery: An Evidence-Based Approach.
- Information Retrieval & Machine Learning!
In addition, if Hutchinson's ranking algorithm is to be used, it will be necessary to force the system to view a parallel score variable at a high VP ratio as an array of scores at a VP ratio of 1; the details are beyond the scope of this discussion. Taking into account the VP ratio used in signature scoring, the ranking time will be: Substituting the standard values for N terms , N ret , , and S words gives us a scoring time of: The times for various sizes of database, on a machine with 65, processors, are as follows: In such cases it is necessary that the signature file reside on either secondary or tertiary storage.
Such a file can then be searched by repetitively 1 transferring signatures from secondary storage to memory, 2 using the above signature-based algorithms to score the documents, and 3 storing the scores in a parallel array. When the full database has been passed through memory, any of the above ranking algorithms may be invoked to find the best matches. The algorithms described above need to be modified, but the compute time should be unchanged. There will, however, be the added expense of reading the signature file into primary memory. As a result, it is necessary to execute multiple queries in one batch in order ot make good use of the compute hardware.
This is done by repeatedly 1 transferring signatures from secondary storage to memory: When all signatures have been read, the ranking algorithm is called once for each query. Again, the algorithms described above need modification, but the basic principles remain unchanged. Given the above parameters, executing batches of queries seems reasonable, yielding the following times: It is possible, however, for a probe to return present for a word that was never inserted.
This is referred to variously as a false drop or a false hit.
The probability of a false hit depends on the size of the signature, the number of hash codes, and the number of bits set in the table. The number of bits actually set depends, in turn, on the number of words inserted into the table. The following approximation has proved useful: There is a trade-off between the false hit probability and the amount of space required for the signatures.
As more words are put into each signature i. We will now evaluate the effects of signature parameters on storage requirements and the number of false hits. A megabyte of text contains, on the average, R docs documents, each of which requires an average of signatures. Each signature, in turn, requires bytes of storage.
Multiplying the two quantities yields the number of bytes of signature space required to represent 1 megabyte of input text. This gives us a compression factor 6 of: If we multiply the number of signatures per megabyte by P false , we get the expected number of false hits per megabyte: We can now examine how varying S words alters the false hit probability and the compression factor: S words S bits P false 80 1. The degree to which computational load may be reduced by increasing signature size is limited by its effect on storage requirements.
For the database parameters assumed above, it appears that a signature size of bits is reasonable. There are two main disadvantages. First, as noted by Salton and Buckley and by Croft , signatures do not support general document-term weighting, a problem that may produce results inferior to those available with full document-term weighting and normalization. This limits the practical use of parallel signature files to relatively small databases which fit in memory.
Parallel signature files do, however, have several strengths that make them worthy of consideration for some applications. First, constructing and updating a signature file is both fast and simple: This makes them attractive for databases which are frequently modified. Third, signature representations work well with serial storage media such as tape. Given recent progress in the development of high-capacity, high-transfer rate, low-cost tape media, this ability to efficiently utilize serial media may become quite important.
In any event, as the cost of random access memory continues to fall, the restriction that the database fit in primary memory may become less important. For example, the following source file: Postings may contain additional information needed to support the search method being implemented. For example, if document-term weighting is used, each posting must contain a weight.
In the event that a term occurs multiple times in a document, the implementer must decided whether to generate a single posting or multiple postings.